Il presente e, ancor più il prossimo futuro, è caratterizzato dall’enorme volume di informazioni accumulato in forme e fonti estremamente diverse e distribuite ampiamente nello spazio fisico e virtuale. La rispondenza ai bisogni dei cittadini e dei consumatori è strettamente collegata ad un processo che ne preveda la migliore disponibilità possibile, al fine di consentire un’erogazione di servizi personalizzati, garantendo al contempo un’orchestrazione di modalità e regole che creino un connubio tra efficienza, efficacia, qualità e rispetto del diritto alla privacy. La grande mole di dati disponibili (Big data), anche in buona parte raccolta e resa disponibile, da tempo, dalle istituzioni pubbliche (Open data), apre a nuovi scenari facendo anche emergere i limiti attuali e le esigenze di miglioramento da affrontare come comunità sociale, prima ancora che attraverso le sole iniziative imprenditoriali private.
Dati, informazioni e conoscenza
Normalmente, e in particolare come semplici cittadini fruitori quotidiani del “digitale, non facciamo una gran differenza tra dati e informazioni. Al massimo tendiamo a dare istintivamente al termine conoscenza un significato superiore, come derivazione di un processo di sintesi ad un livello più elevato che deriva da un’analisi precedente di dati e informazioni in grado di offrirci una visione più ampia e un modello della realtà, o di una parte di essa, che ci aiuta a effettuare valutazioni, scelte e prendere decisioni.
In realtà i dati si presentano sotto varie forme: numeri, lettere dell’alfabeto, parole, immagini, suoni, simboli ecc. A essi si deve attribuire un significato, metterli in relazione tra di loro affinché rappresentino una realtà d’interesse, creando dei livelli di sintesi che portano al concetto stesso di informazione. La stessa operazione di porli in relazione tra loro, così apparentemente scontata dal punto di vista umano, non risulta affatto banale, dipendendo sempre da un dominio di applicazione che è influenzato da un innumerevole insieme di elementi correlati a:
ampia disponibilità di dati
affidabilità, coerenza e congruità dei dati
contesto di interesse
esigenze e scopi di impiego e applicazione
La provenienza, l’ubicazione e la forma dei dati è molteplice e varia, ad esempio:
valori numerici e misure numerici provenienti dai sensori dell’IoT (Internet of Things), compresi i nostri elettrodomestici, smartphone/tablet ecc., oppure prodotti da noi stessi attraverso l’impiego di servizi e strumenti digitali come le dichiarazioni dei redditi, le operazioni bancarie, l’uso di mezzi di trasporto, i dati forniti per un censimento, la nostra posizione nello spazio fisico, ecc.
quelli, in forme molteplici, che generiamo quotidianamente sul web in forme non strutturate sotto forma di commenti, opinioni, articoli, fotografie e filmati
quelli raccolti dalle diverse istituzioni pubbliche e private ai fini più disparati
Se quindi un dato è ciò che è immediatamente presente alla conoscenza prima di ogni elaborazione, umana o informatica, ciò che conduce all’informazione, e quindi, alla conoscenza, è un processo di affinamento e miglioramento senza i quali il processo stesso perde ogni carattere di valore e opportunità.
Il processo richiede inevitabilmente di procedere secondo una sequenza di passi successivi, riassumibili come:
dall’osservazione di una porzione della realtà si determinano i fatti di interesse.
dai fatti un campionamento finito di essi ci porta ai dati (raccolti da sensori, disseminati sul web, accumulati in un archivio pubblico ecc.).
dai dati, operazioni di analisi ci conducono, attraverso l’interpretazione e la sintesi, alle informazioni.
dalle informazioni attraverso un processo di estrazione di relazioni e di significati a più alto livello perveniamo alla conoscenza, individuando schemi, modelli e logiche di sistema della porzione di realtà di interesse.
l’accumulo di conoscenza in relazione, anche a differenti campi o domini di applicazione, tende a farci pervenire a quella che potremmo definire come saggezza, intesa come equilibrio di comportamento e visione della realtà frutto di una matura consapevolezza ed esperienza delle cose del mondo.
E’ lecito a questo punto chiedersi il perché di questa “tiritera”, forse ovvia e scontata per i più. Perché anche in un processo digitale il metodo non è differente e meno esente da complessità e criticità dipendenti da:
l’enorme volume di dati disponibili (disponibilità).
Le modalità di campionamento (ossia qualificazione, coerenza, congruità già all’origine).
un’enorme mole di lavoro necessaria per metterli in relazione, creando informazioni di sintesi e di significato.
un’altrettanto enorme mole di lavoro sulle informazioni per individuare schemi e modelli di conoscenza possibile e applicabile.
Pertanto è evidente, che tanto più i dati o le informazioni all’origine, sono facilmente disponibili, congrui, coerenti senza ridondanze e duplicazioni, agevolmente accessibili e utilizzabili, tanto più le fasi seguenti risulteranno più facilmente ed economicamente applicabili, con una maggior varietà e qualità dei servizi disponibili attraverso essi.
Ripetiamoci insieme dove va il mondo
Nel mondo odierno, e in particolare del futuro, si legge e si sente continuamente che “informazioni e conoscenza sono la vera ricchezza da valorizzare attraverso il motore della digitalizzazione”.
Sia nel pubblico che nel privato si tende a sistemi e piattaforme capaci di condividere dati, informazioni e conoscenza i quali, sotto la regia di funzioni di orchestrazione, siano in grado di attuare e soddisfare automaticamente le regole e le policy prefissate. In un’impresa privata le regole saranno quelle organizzative e del modello di business, mentre a livello pubblico saranno quelle che derivano da leggi, normative, procedure organizzative e di attuazione di enti e uffici, sempre più integrati ed automatizzati.
In ogni caso l’obiettivo generale, a fini di efficienza ed efficacia, tende a essere quello di rispondere alle richieste sempre più personali e personalizzate degli utenti, instradandole automaticamente, rispondendo tempestivamente, sino all’anticiparle esse stesse con possibilità anche di autodattamento al variare nel tempo delle situazioni di contesto (leggi e norme, condizioni personali, ecc.).
Capacità di interpretazione e anticipazione
Il miglioramento del servizio ai cittadini e lo sviluppo di nuovi servizi privati, dalle indagini di marketing e di esigenze sociali sino alla definizione di modelli di business o di erogazione di servizi pubblici, richiede la disponibilità da molte fonti di informazioni “pulite”. Molte di esse sono già disponibili a livello pubblico: censimenti, utilizzo e accesso dei cittadini a servizi pubblici e, sia pur con grande attenzione agli aspetti di privacy, dai nostri stessi comportamenti e impieghi dei più recenti strumenti digitali.
Nel pubblico, ad arricchire la quantità e la varietà di dati e informazioni dei big data, concorrono già da tempo gli open data messi a disposizione da istituzioni pubbliche, in formato aperto e utilizzabile. Ad esempio anche il Comune di Bologna ha iniziato da alcuni anni a sviluppare una politica di trasparenza e accessibilità, consentendo a cittadini, associazioni e imprese una partecipazione attiva nella condivisione di dati e informazioni. Il tutto nasce da un logico e, in larga parte, sincero convincimento di costruire un nuovo modello di sviluppo economico e culturale improntato al concetto di open government, che consenta ai diversi portatori di interesse di utilizzare dati e informazioni, valorizzandoli attraverso forme diverse, efficienti ed efficaci, al fine di migliorare accessibilità e comprensione attraverso nuove applicazioni e servizi a beneficio di tutta la comunità.
L’apertura delle “banche dati” pubbliche si inserisce pertanto in questo contesto e, allo stato attuale, si traduce per lo più in un percorso di condivisione di dataset (collezioni di dati) provenienti da fonti e archivi diversi, raccolti con criteri di sintesi e aggiornati periodicamente, fruibili in modo tecnicamente aperto da qualunque altro soggetto privato o pubblico.
Tuttavia, ad oggi, parlando di open data pubblici, che costituiscono un grande patrimonio per l’intera comunità, si deve constatare come tali dati, o a volte, vere informazioni, derivino usualmente da archivi molto diversi tra loro, non integrati e che non comunicano, costringendo a onerosi lavori di recupero, pulizia e sintesi che determinano frammentazione, ritardi negli aggiornamenti e una messa in disponibilità sotto forme che a loro volta richiedono da parte degli utilizzatori ulteriori operazioni di verifica, scrematura e messa in relazione dei contenuti tra loro.
Ad esempio per il Comune di Bologna esiste una mappa precisa dei materiali disponibili. I domini di interesse sono molteplici:
patrimonio storico/artistico
servizi e informazioni turistiche
mobilità
GIS, cartografia e sistemi territoriali
Welfare, servizi e sportelli sociali
ecc.
I dataset attuali, sia pur organizzati e raggruppati tematicamente, sono in generale disponibili separatamente come elementi a se stanti senza significative relazioni con altri differenti dataset, della stessa o di altre tematiche, in formati facilmente utilizzabili (CSV, XML, ecc) ma, in quanto tali, soggetti alla necessità, da parte degli utilizzatori, di importanti attività di conversione, rianalisi e messa in relazione tra loro.
Ad esempio supponiamo di essere una “startup” che voglia realizzare un servizio di supporto al turista e al cittadino, con un’applicazione che dal nostro smartphone:
sappia dove ci troviamo (ad es. a Bologna).
sappia quali sono i nostri interessi (professione, arte, scienza, spettacoli, ecc) e il nostro profilo (lingua, città/paese di provenienza ecc).
ci segnali, a seconda di dove ci troviamo e del nostro profilo/interessi, cosa possa esservi di interessante per noi nelle vicinanze.
ci segnali dei percorsi notevoli di visita storico/artistici o di svago.
si preoccupi di fornirci tutte le informazioni storiche e culturali o di svago necessarie.
ci sia di aiuto nella scelta e nell’utilizzo dei mezzi di trasporto pubblici per raggiungere al meglio i nostri luoghi di interesse.
Nel caso del Comune di Bologna occorrerebbe attingere separatamente ai dataset di una ampia serie di tematiche, rielaborarli ponendoli in carico ad una propria banca dati in cui i diversi dati e informazioni vengono posti in relazione tra loro (ad esempio i mezzi pubblici per raggiungere efficientemente i diversi siti storici/culturali o di svago) e, in molti casi, ricavare informazioni da archivi documentali non strutturati in linguaggio naturale, come ad esempio nel caso degli open data relativi a storia e arte per i quali, oltre alla sintesi dello specifico dataset, si rimanda a pagine e indirizzi specifici contenenti ampie descrizioni scritte, supporti audiovisivi e altro.
Oltre a questa onerosa attività di acquisizione, elaborazione e sintesi da fonti molteplici andrebbe poi aggiunta quella finalizzata a garantirne l’aggiornamento costante.
E’ evidente, anche solo concettualmente senza coinvolgere aspetti informatici, che tanto più questo onere si sposta verso il lato di impiego, tanto più aumenta il costo e la difficoltà di garantirne una buona qualità. Per il costo poi si osserva che non ci riferisce solo al costo per la singola startup, pure importante, ma a quello complessivo di comunità, dove si considerasse l’inutile somma di tali costi sostenuti da diverse imprese private per effettuare separatamente e ripetutamente pre-elaborazioni di informazioni che, se effettuate unicamente all’origine, laddove dati e informazioni nascono, amplificherebbero le potenzialità di ogni singolo operatore privato, liberandolo da un’ampia gamma di oneri intermedi e sussidiari, ma comunque necessari.
E questo porta all’indispensabilità del “Government as a Platform”, come ampiamente descritto nei suo concetti, tra gli altri, da Tim O’Really .
L’evoluzione naturale del government as a platform appare cioè sempre più quella di passare dall’esporre dati e informazioni a quella di esporre servizi basati su regole e policy governati da un software “orchestratore”, ossia al tendere verso un software defined government e una software defined bank.
Dal punto di vista pratico ciò significa passare dalla “semplice” disponibilità di dati e informazioni aperti, portati agli utilizzatori in forma elementare e disgiunta, da rielaborare e aggiornare ogni volta, alla disponibilità di servizi software che permettano di interrogare e richiedere dati e informazioni già utili e relazionati nel momento in cui è necessario, utilizzando le stesse relazioni già precostituite in origine come un mezzo per renderne ancora più efficace ed efficiente il loro impiego.
Ciò unito alla “profilazione” dei nostri interessi e comportamenti accrescerebbe ulteriormente le potenzialità di ogni servizio. Naturalmente la criticità è costituita dalla rigorosa definizione e governo dei confini legati al rispetto della privacy individuale. Ma del resto se stiamo ormai sempre più accettando di venir “profilati” per venderci pubblicità o servizi commerciali perché non esserlo per venir serviti meglio anche dalla PA.
Ad esempio potremmo essere avvisati direttamente che abbiamo i requisiti per ottenere uno specifico beneficio, secondo una nuova normativa.
La richiesta di una licenza edilizia potrebbe essere fatta attraverso dei servizi applicativi in grado di verificare le informazioni presenti nei diversi archivi, procedendo subito con il via libera o meno. Al cittadino spetterebbe solo di inserire la richiesta con le eventuali informazioni aggiuntive.
In una rete di servizi interconnessi potrebbero essere rilevate in tempo reale anche piccole trasgressioni, con “minimulte” o un richiamo, segnalando in automatico un comportamento sbagliato, incentivando comportamenti socialmente accettabili e riservando provvedimenti tempestivi di maggior rilievo solo in caso di recidività o estrema gravità.
E non si dica che è complicato … altri lo stanno già facendo
Abbiamo certamente nel nostro Paese gli ingegneri e le competenze per farlo. Forse quello che ci manca è una volontà che nasca per prima da un senso d’interesse della comunità piuttosto che del singolo o del piccolo gruppo, e da una visione non al breve, ma al lungo termine.
Ad esempio in Estonia è attiva da tempo una piattaforma governativa di integrazione (X-ROAD) che permette di scambiare servizi e informazioni attraverso strumenti tecnologici di interrogazione a diversi database e che costituisce la base di un sistema articolato di servizi per il cittadino sviluppati sia dal pubblico che dai privati.
In X-ROAD i data base sono per forza di cose decentrati e non esiste un unico proprietario o controllore. Tuttavia la piattaforma ne consente l’interazione, l’integrazione, l’accesso e l’utilizzo distribuito e, potremmo dire, utilmente “pre-digerito” ai fini delle diverse possibili applicazioni.
Ogni ente, agenzia governativa o impresa sceglie i servizi più idonei tra quelli disponibili e i servizi possono essere aggiunti in ogni momento attraverso regole di standardizzazione condivise.
In 2013 e-Estonia:
Oltre 287 millioni di interrogazioni attraverso X-Road.
Oltre 170 banche dati integrate attraverso i servizi di X-Road.
Oltre 2000 servizi disponibili attraverso X-Road.
Oltre 900 organizzazioni utilizzavano quotidianamente X-Road.
Più del 50%dei cittadini dell’Estonia facevano uso di portali basati su X-Road
Per l’ampia parte degli open data che derivano dal pubblico e hanno una ricaduta nel sociale, anche attraverso servizi privati, non si può pretendere di attribuire ai soli privati la responsabilità di scelte ottimali e condivise in grado di mediare efficacemente tra le esigenze di un’intera comunità e i legittimi interessi commerciali e competitivi degli operatori a diverso titolo. La ricerca di standard comuni si tradurrebbe, come spesso sino ad oggi, più in uno scontro tra i “player” del mercato, favorendo al contempo quelli più forti e, di fatto gli interessi multinazionali prima ancora che quelli di una comunità.
Sulla diversa natura di dati e informazioni nel mondo digitalizzato
Come già accennato, il “dispiegamento” nel mondo attuale di dati e informazioni è assai vasto e in forme molteplici. La sintesi offertaci dagli open data è solo una parte dell’insieme disponibile.
Il “web” è un’inesauribile fonte di altri dati e informazioni, stratificate nel tempo e contenenti idee, comportamenti, modelli culturali ed elementi di dettaglio sfuggiti da un lato all’opera di classificazione in contenitori strutturati e, dall’altro, a quella di formulazione di relazioni tra contenuti non strutturati come pagine web, articoli, commenti ecc.
Del resto, in ogni caso, moltissime di queste informazioni sono contenute in materiali che ognuno di noi concorre quotidianamente a condividere sulla “rete” o in azienda: opinioni, suggerimenti, idee, pensieri, riflessioni più o meno articolate, ecc
Anche moltissimi dei documenti, sia pubblici che aziendali, hanno le stesse caratteristiche, quelle di riportare una gran quantità di dati e informazioni espressi in forma non strutturata, in linguaggio naturale.
Si intreccia quindi l’ulteriore esigenza di saper interpretare, attraverso opportuni processi digitali, il linguaggio naturale, nelle diverse lingue, afferrandone il meglio possibile il significato ed estraendone informazioni che altrimenti sarebbero perdute o, comunque, non facilmente accessibili o relazionabili tra loro.
Riconoscere informazioni non significa eseguire ricerche su testo indicizzato, sapendo cioè quali e quante parole sono utilizzate in ogni documento, con al più la conoscenza delle relazioni di sinonimia e tecniche di previsione o sostituzione delle parole più probabili che seguono.
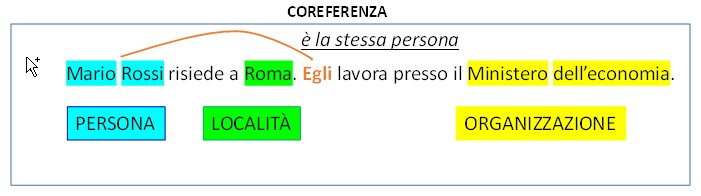
Significa comprendere il significato della frase o almeno di un numero sufficiente di forme espressive, e, attraverso la comprensione, estrarre i concetti (entità) e le proprietà (informazioni), inoltre significa comprendere le relazioni tra concetti diversi, le quali si possono rappresentare anche attraverso le stesse proprietà (quando uno a uno) o in collegamenti tra istanze di entità diverse (quando molti a molti).
La comprensione semantica è strettamente dipendente dalla lingua (italiano, inglese,…), dalla sua grammatica, e da terminologie e forme espressive tipiche del contesto (dominio).
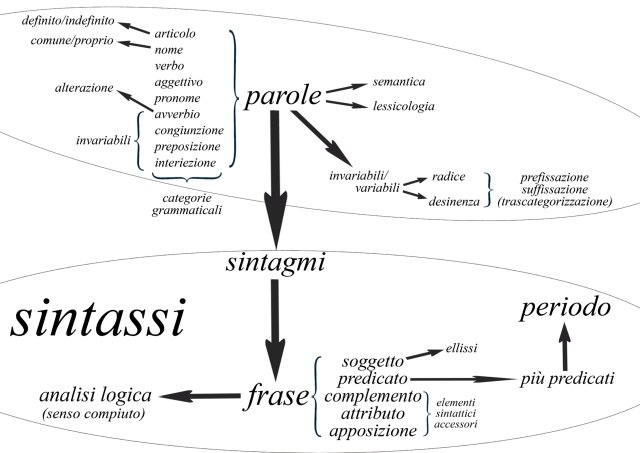
Interpretare il linguaggio naturale è un’operazione complessa che richiede di effettuare un’analisi lessicale basata su uno o più vocabolari al fine di determinare le caratteristiche di ogni singola parola (es. nome, articolo, verbo, ecc. singolare/plurale, maschile/femminile, voce del verbo all’infinito, tempo, ecc). Di eseguire nel seguito un’analisi sintattica al fine di stabilire come le parole sono in relazione tra di loro in una frase ( es.: soggetto, verbo, complemento oggetto). Infine di risolvere le ambiguità semantiche a livello di singola parola o di frase utilizzando spesso elementi di “pragmatica” che vanno oltre alla frase e al documento corrente, come ad esempio la conoscenza del ruolo dei soggetti coinvolti, la collocazione spazio-temporale della situazione, la conoscenza generale dell’argomento trattato.
L’interpretazione del linguaggio naturale al fine di individuare ed estrarre entità, proprietà e relazioni è un processo assai articolato che può essere sviluppato attraverso diverse tecniche e risulta ormai sempre più uno dei fattori fondamentali per una piena e completa utilizzazione di big data e open data.
Senza qui poter entrare nel dettaglio, per ragioni di sintesi, gli approcci utilizzabili sono sostanzialmente due: “machine learning” e “rule based”.
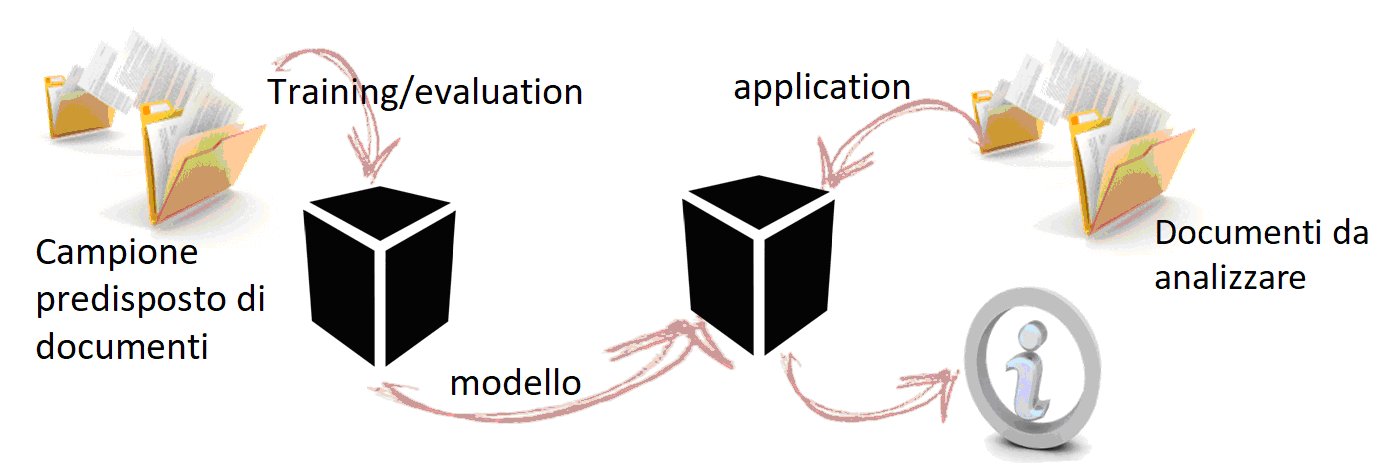
In estrema sintesi con il “machine learning”, in fase di apprendimento, si applica ad una “scatola nera” un sufficientemente ampio campione di espressioni o documenti in ingresso, nei quali siano state indicate le informazioni da individuare ed estrarre. Ciò consente di generare un “modello” in base al quale riapplicando alla “scatola nera” un diverso insieme di espressioni o documenti, in questo caso privi di indicazioni, essa produrrà una sua proposta di informazioni (entità, proprietà, relazioni), ciascuna corredata da una misura di accuratezza o probabilità.
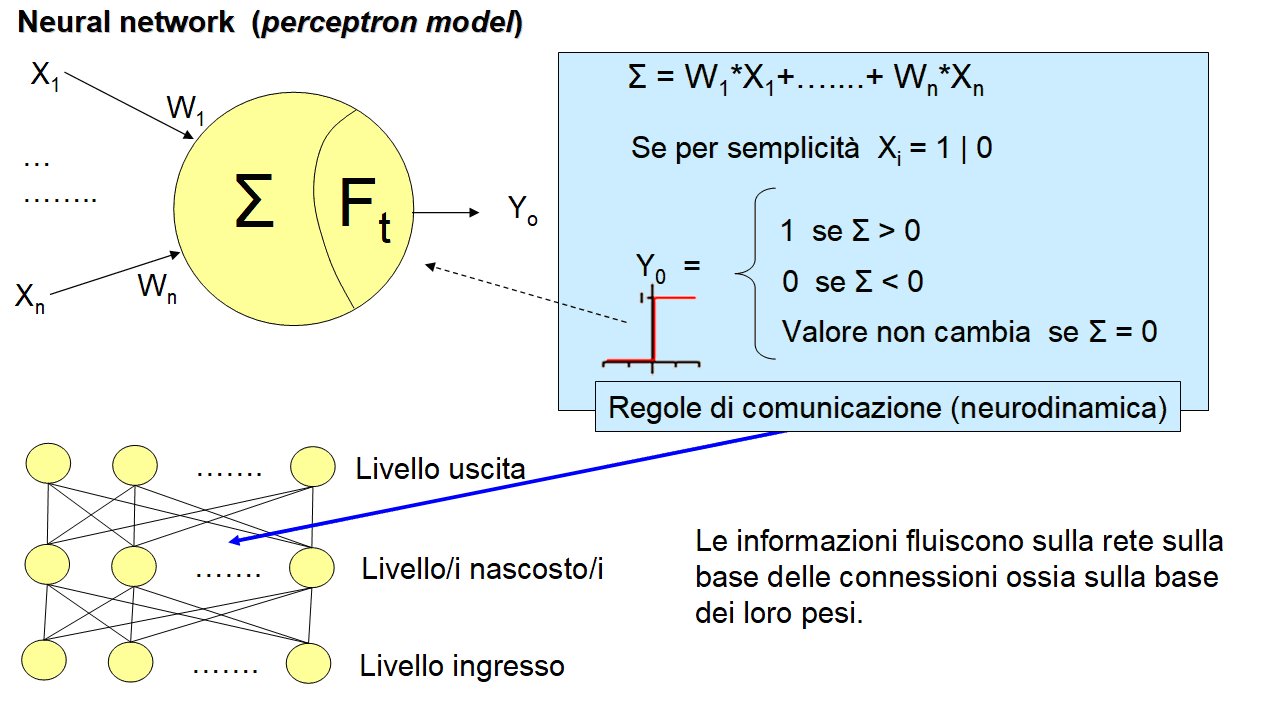
La “scatola nera” è un oggetto tecnologico di diversa natura. Può utilizzare algoritmi di natura unicamente statistica volti a determinare dalle caratteristiche degli elementi nell’intorno delle informazioni indicate nel campione come di “uscita”, quelle che meglio e con maggior probabilità sono in grado di portare all’individuazione delle medesime informazioni su fonti diverse da quelle di addestramento. Oppure possono ispirarsi, come nel caso delle “neural network” per il “deep learning”, all’emulazione dei comportamenti associativi tipici del nostro cervello attraverso la trasmissione dei segnali elettrici tra i neuroni, mediante le connessioni sinaptiche. Nel primo caso l’addestramento determina un modello statistico di distribuzione di proprietà specifiche più probabili per individuare determinati risultati, mentre nel secondo caso l’addestramento ha lo scopo di determinare la struttura migliore dei collegamenti e del loro peso nella trasmissione dei segnali tra i neuroni per il risultato.
In particolare per le “neural network”, a seconda dei casi di applicazione e delle tecniche impiegate, sono possibili anche forme di addestramento non supervisionato, ossia sotto forma, magari parziale, di autoapprendimento dai risultati prodotti in corso di esercizio oppure tecniche di apprendimento rinforzato dalle indicazioni correttive di un utilizzatore durante l’uso.
In entrambi i casi il tutto si traduce nella necessità di elevate capacità di calcolo vettoriale/matriciale a cui i recenti sviluppi nell’impiego di GPU (Graphic Processing Unit), dotate di numerosi coremultithread, unite a piattaforme e frame-work basati su linguaggi di programmazione parallela permettono ormai oggi di conseguire importanti risultati anche senza l’impiego di hardware o reti di apparati dedicati.
Nell’approccio “rule based” si fa ricorso ad una serie di tecniche e algoritmi consolidati e disponibili, applicati in sequenza e finalizzati, in estrema sintesi, alla:
scomposizione di un testo nei suoi componenti chiave, detti token: parole numeri, punteggiatura
l’attribuzione ai token delle caratteristiche lessicali/morfologiche
l’integrazione ai token, o a sequenze di token, del riferimento alla loro eventuale appartenenza a dizionari, glossari specifici, eventualmente suddivisibili per tematiche o categorie di contesto
la costruzione di un albero sintattico finalizzato all’individuazione della struttura di ogni frase
l’analisi semantica sulla base di grammatiche scritte con linguaggi specifici di “text engineering” che utilizzano tutte le informazioni prima raccolte, per pervenire ad una interpretazione semantica che consenta di individuare ed estrarre le informazioni ricercate.
Ferma l’importanza di valutare e scegliere le tecniche, gli strumenti e gli algortimi più adatti, può essere in generale osservato che in “machine learning” prevale in genere l’ impegno di addestramento e verifica, mentre in “rule based” prevale quello di disegnare un insieme efficace di glossari e grammatiche di regole.
In entrambi i casi è richiesto un team con un equilibrato mix di competenze ed esperienze in campo linguistico, conoscenza del dominio e padronanza degli strumenti tecnologici.
Inoltre gli approcci “rule based” e “machine learning” non sono necessariamente mutuamente esclusivi, ma possono essere combinati a seconda delle situazioni e di considerazioni pragmatiche attinenti al contesto, ai risultati, alle modalità, ai tempi e ai costi.
Ai fini realizzativi e di impiego è altresì fondamentale la scelta delle piattaforme e degli strumenti tecnologici più adatti al fine di realizzare applicazioni di “text engineering”. Diverse sono oggi le piattaforme disponibili, sia nella connotazione “open source” che proprietaria, sia come servizi cloud a consumo che come pacchetti “on premise”, ossia su propri sistemi locali o in cloud privato.
Inoltre correlabile agli open data e di estrema importanza e utilità sarebbe, nel caso della lingua italiana, la disponibilità di vocabolari e glossari specializzati in contesti e domini diversi, ancora oggi di assai difficile reperimento.
Conclusioni
Anche se il mondo non è entrato da molto tempo in uno scenario di capillare condivisione di dati e informazioni, sono già tuttavia grandi i volumi e la quantità dettagliata di elementi informativi estraibili e utilizzabili. La facilità, l’efficienza e l’efficacia di utilizzo aumenta drasticamente tanto più l’affinamento e il processo di qualificazione da dati a informazioni inizia ad avvenire in prossimità della loro origine, mettendo a disposizione degli utilizzatori dei complessi informativi più organici e gestibili. Non sempre ciò è possibile o economicamente sostenibile, ma per quanto riguarda la porzione dei big data relativa agli open data resi disponibili dalle PA, è auspicabile la definizione ed il raggiungimento di standard comuni e di una piattaforma di servizi almeno nazionale, in grado di ridurre drasticamente costi e investimenti necessari all’iniziativa privata per intraprendere la realizzazione di nuovi servizi basati su tali informazioni, migliorandone al contempo l’efficacia e amplificando ulteriormente le potenzialità di comunicazione e scambio tra applicazioni diverse e con le stesse banche dati di origine .
Questo portale, per consertirti una migliore esperienza d'uso, utilizza unicamente cookie tecnici, Non utilizza cookie analitici/statistici, anonimi e non. Non utilizza cookie di profilazione personale, propri o di terze parti, a fini pubblicitari e di vendita


 Sommario
Sommario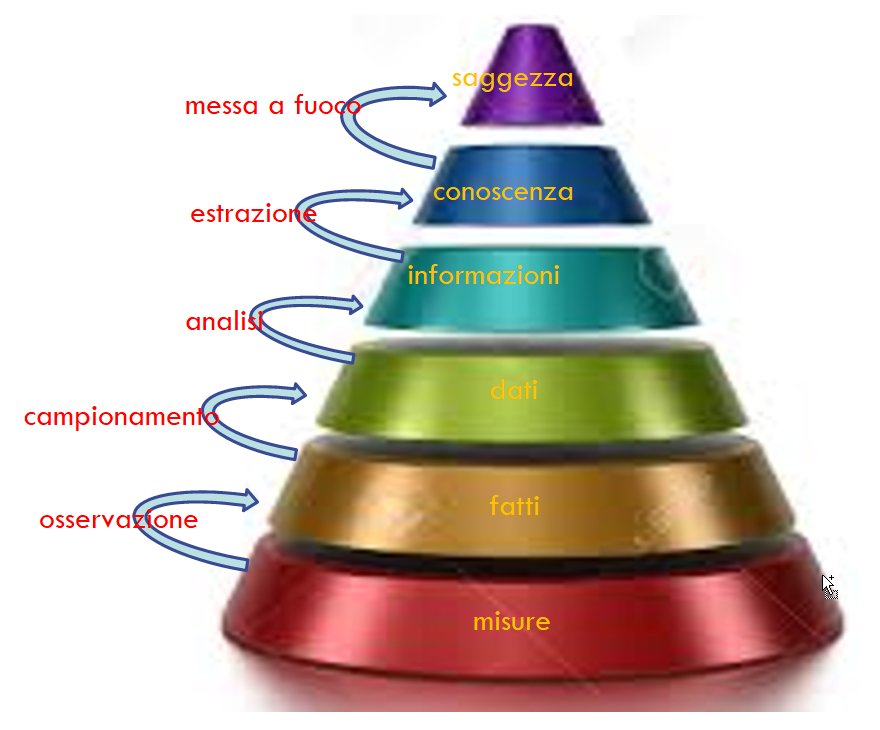
 Nel mondo odierno, e in particolare del futuro, si legge e si sente continuamente che “informazioni e conoscenza sono la vera ricchezza da valorizzare attraverso il motore della digitalizzazione”.
Nel mondo odierno, e in particolare del futuro, si legge e si sente continuamente che “informazioni e conoscenza sono la vera ricchezza da valorizzare attraverso il motore della digitalizzazione”.
 Anche moltissimi dei documenti, sia pubblici che aziendali, hanno le stesse caratteristiche, quelle di riportare una gran quantità di dati e informazioni espressi in forma non strutturata, in linguaggio naturale.
Anche moltissimi dei documenti, sia pubblici che aziendali, hanno le stesse caratteristiche, quelle di riportare una gran quantità di dati e informazioni espressi in forma non strutturata, in linguaggio naturale.
 un’analisi lessicale basata su uno o più vocabolari al fine di determinare le caratteristiche di ogni singola parola (es. nome, articolo, verbo, ecc. singolare/plurale, maschile/femminile, voce del verbo all’infinito, tempo, ecc). Di eseguire nel seguito un’analisi sintattica al fine di stabilire come le parole sono in relazione tra di loro in una frase ( es.: soggetto, verbo, complemento oggetto). Infine di risolvere le ambiguità semantiche a livello di singola parola o di frase utilizzando spesso elementi di “pragmatica” che vanno oltre alla frase e al documento corrente, come ad esempio la conoscenza del ruolo dei soggetti coinvolti, la collocazione spazio-temporale della situazione, la conoscenza generale dell’argomento trattato.
un’analisi lessicale basata su uno o più vocabolari al fine di determinare le caratteristiche di ogni singola parola (es. nome, articolo, verbo, ecc. singolare/plurale, maschile/femminile, voce del verbo all’infinito, tempo, ecc). Di eseguire nel seguito un’analisi sintattica al fine di stabilire come le parole sono in relazione tra di loro in una frase ( es.: soggetto, verbo, complemento oggetto). Infine di risolvere le ambiguità semantiche a livello di singola parola o di frase utilizzando spesso elementi di “pragmatica” che vanno oltre alla frase e al documento corrente, come ad esempio la conoscenza del ruolo dei soggetti coinvolti, la collocazione spazio-temporale della situazione, la conoscenza generale dell’argomento trattato.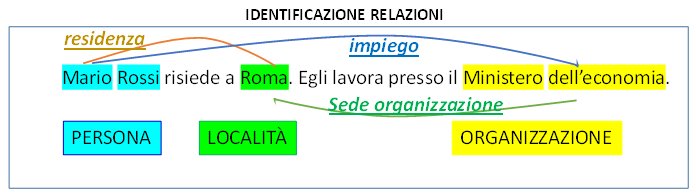

 & Information Extraction (IE)")
: dai social media alla collaborazione globale")

 del Committente")
Lascia un commento